ENV
Node IP
| Node | IP |
|---|---|
| s7kuberma01 | 10.1.51.31 |
| s7kuberma02 | 10.1.51.32 |
| s7kuberma03 | 10.1.51.33 |
| s7kubersla01 | 10.1.51.34 |
| s7kubersla02 | 10.1.51.35 |
vi /etc/hosts
10.1.51.31 s7kuberma01
10.1.51.32 s7kuberma02
10.1.51.33 s7kuberma03
10.1.51.34 s7kubersla01
10.1.51.35 s7kubersla02
architecture looks like this
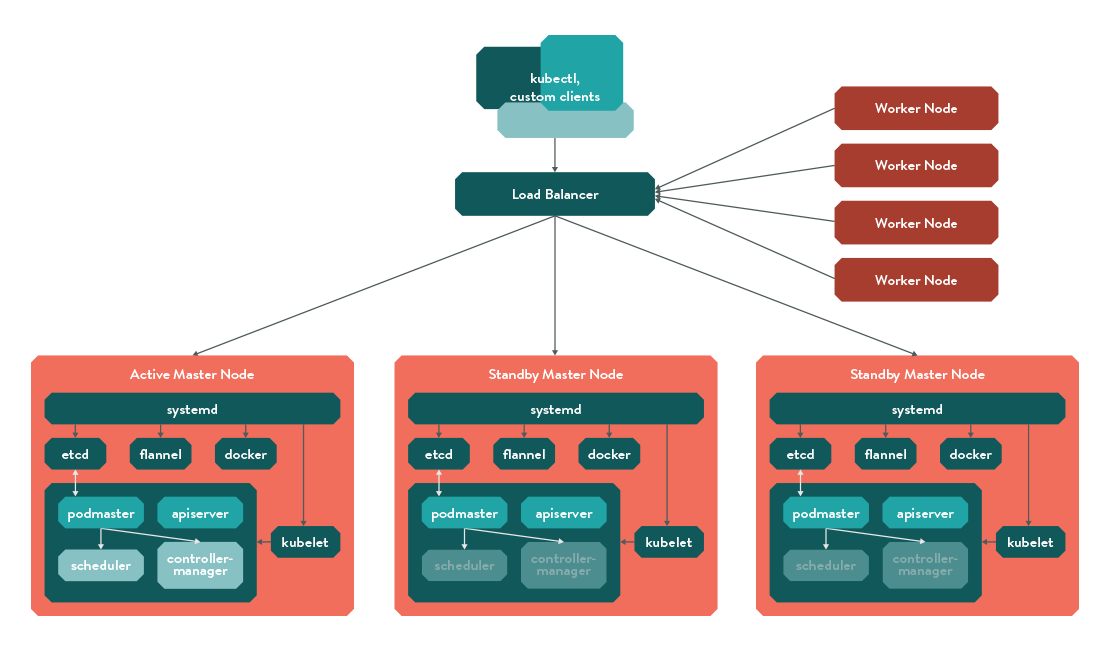
Master Nodes
install etcd cluster in the 3 master nodes
yum install -y etcd
Configuration
vi /etc/etcd/etcd.conf
s7kuberma01 etcd
# [member]
ETCD_NAME=s7kuberma01
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
#ETCD_WAL_DIR=""
#ETCD_SNAPSHOT_COUNT="10000"
#ETCD_HEARTBEAT_INTERVAL="100"
#ETCD_ELECTION_TIMEOUT="1000"
ETCD_LISTEN_PEER_URLS="http://10.1.51.31:2380"
ETCD_LISTEN_CLIENT_URLS="http://10.1.51.31:2379,http://localhost:2379"
#ETCD_MAX_SNAPSHOTS="5"
#ETCD_MAX_WALS="5"
#ETCD_CORS=""
#
#[cluster]
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://10.1.51.31:2380"
# if you use different ETCD_NAME (e.g. test), set ETCD_INITIAL_CLUSTER value for this name, i.e. "test=http://..."
ETCD_INITIAL_CLUSTER="s7kuberma01=http://10.1.51.31:2380,s7kuberma02=http://10.1.51.32:2380,s7kuberma03=http://10.1.51.33:2380"
ETCD_INITIAL_CLUSTER_STATE="new"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_ADVERTISE_CLIENT_URLS="http://10.1.51.31:2379"
s7kuberma02 etcd
# [member]
ETCD_NAME=s7kuberma02
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
#ETCD_WAL_DIR=""
#ETCD_SNAPSHOT_COUNT="10000"
#ETCD_HEARTBEAT_INTERVAL="100"
#ETCD_ELECTION_TIMEOUT="1000"
ETCD_LISTEN_PEER_URLS="http://10.1.51.32:2380"
ETCD_LISTEN_CLIENT_URLS="http://10.1.51.32:2379,http://localhost:2379"
#ETCD_MAX_SNAPSHOTS="5"
#ETCD_MAX_WALS="5"
#ETCD_CORS=""
#
#[cluster]
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://10.1.51.32:2380"
# if you use different ETCD_NAME (e.g. test), set ETCD_INITIAL_CLUSTER value for this name, i.e. "test=http://..."
ETCD_INITIAL_CLUSTER="s7kuberma01=http://10.1.51.31:2380,s7kuberma02=http://10.1.51.32:2380,s7kuberma03=http://10.1.51.33:2380"
ETCD_INITIAL_CLUSTER_STATE="new"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_ADVERTISE_CLIENT_URLS="http://10.1.51.32:2379"
s7kuberma03 etcd
# [member]
ETCD_NAME=s7kuberma03
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
#ETCD_WAL_DIR=""
#ETCD_SNAPSHOT_COUNT="10000"
#ETCD_HEARTBEAT_INTERVAL="100"
#ETCD_ELECTION_TIMEOUT="1000"
ETCD_LISTEN_PEER_URLS="http://10.1.51.33:2380"
ETCD_LISTEN_CLIENT_URLS="http://10.1.51.33:2379,http://localhost:2379"
#ETCD_MAX_SNAPSHOTS="5"
#ETCD_MAX_WALS="5"
#ETCD_CORS=""
#
#[cluster]
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://10.1.51.33:2380"
# if you use different ETCD_NAME (e.g. test), set ETCD_INITIAL_CLUSTER value for this name, i.e. "test=http://..."
ETCD_INITIAL_CLUSTER="s7kuberma01=http://10.1.51.31:2380,s7kuberma02=http://10.1.51.32:2380,s7kuberma03=http://10.1.51.33:2380"
ETCD_INITIAL_CLUSTER_STATE="new"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_ADVERTISE_CLIENT_URLS="http://10.1.51.33:2379"
Enable and start etcd cluster
systemctl enable etcd;systemctl start etcd
Check etcd cluster health
etcdctl cluster-health
member 605710dd5e542748 is healthy: got healthy result from http://10.1.51.33:2379
member 73eb2e8e208fa18f is healthy: got healthy result from http://10.1.51.32:2379
member b7760aa41c6d87b3 is healthy: got healthy result from http://10.1.51.31:2379
cluster is healthy
now we have an externel etcd cluster “–external-etcd-endpoints=http://10.1.51.31:2379,http://10.1.51.32:2379,http://10.1.51.33:2379” for kubernetes
Install Kubeadm on the s7kuberma01
repo
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://yum.kubernetes.io/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg
https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
EOF
selinux
setenforce 0
install the packages and enable the services
yum install -y docker kubelet kubeadm kubectl kubernetes-cni
systemctl enable docker && systemctl start docker
systemctl enable kubelet && systemctl start kubelet
VIP
now we prepare to init our kubernetes with the kubeadm tools
but first, for we’re trying to deploy an HA env, we have to use the vip for the HA masters which is “10.1.51.30”, we will achieve this later with “Keepalived”, for right now , let’s just add it in the s7kuberma01.
ip addr add 10.1.51.30/25 dev ens160
and check the IP addresses
ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens160: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000
link/ether 00:0c:29:4d:0a:87 brd ff:ff:ff:ff:ff:ff
inet 10.1.51.31/25 brd 10.1.51.127 scope global ens160
valid_lft forever preferred_lft forever
inet 10.1.51.30/25 scope global secondary ens160
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe4d:a87/64 scope link
valid_lft forever preferred_lft forever
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN
link/ether 02:42:c3:25:5c:ad brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 scope global docker0
valid_lft forever preferred_lft forever
you can see ,now we have both the “10.1.51.30” and “10.1.51.31” on the nic card “ens160” now
Kubeadm init
kubeadm init --api-advertise-addresses=10.1.51.30 --external-etcd-endpoints=http://10.1.51.31:2379,http://10.1.51.32:2379,http://10.1.51.33:2379 --pod-network-cidr 10.244.0.0/16
3 parameters have been used here
- API server pionted to the VIP which is 10.1.51.30
- use the external etcd cluster
- for we will install network addon flannel later , have to set the pod network as “10.244.0.0/16”
If everthing runs well, we should see output like this
Your Kubernetes master has initialized successfully!
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
http://kubernetes.io/docs/admin/addons/
You can now join any number of machines by running the following on each node:
kubeadm join --token=2dd145.8c687822f02702f1 10.1.51.30
Add two more Master nodes
install Packages
install kubelet kubeadmin in the s7kuberma02 s7kuberma03 , but dont start the services, use the same repo
yum install -y docker kubelet kubeadm kubectl kubernetes-cni
copy /etc/kubernetes from s7kuberma01 to 02 and 03 and start the kubelet
scp -r 10.1.51.31:/etc/kubernetes/* /etc/kubernetes/
start docker and kubelet on s7kuberma02 03
systemctl enable docker && systemctl start docker
systemctl enable kubelet && systemctl start kubelet
Deply the dns addons on all the masters
For deploy/kube-dns replicas only =1 ,so we need change 1 to 3 to achieve high availability
kubectl scale deploy/kube-dns --replicas=3 -n kube-system
install network addons
Download kube-flannel.yml from https://github.com/coreos/flannel/blob/master/Documentation/kube-flannel.yml
It should look like below:
---
kind: ConfigMap
apiVersion: v1
metadata:
name: kube-flannel-cfg
namespace: kube-system
labels:
tier: node
app: flannel
data:
cni-conf.json: |
{
"name": "cbr0",
"type": "flannel",
"delegate": {
"isDefaultGateway": true
}
}
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan"
}
}
---
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: kube-flannel-ds
namespace: kube-system
labels:
tier: node
app: flannel
spec:
template:
metadata:
labels:
tier: node
app: flannel
spec:
hostNetwork: true
nodeSelector:
beta.kubernetes.io/arch: amd64
containers:
- name: kube-flannel
image: quay.io/coreos/flannel-git:v0.6.1-62-g6d631ba-amd64
command: [ "/opt/bin/flanneld", "--ip-masq", "--kube-subnet-mgr" ]
securityContext:
privileged: true
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
volumeMounts:
- name: run
mountPath: /run
- name: flannel-cfg
mountPath: /etc/kube-flannel/
- name: install-cni
image: quay.io/coreos/flannel-git:v0.6.1-62-g6d631ba-amd64
command: [ "/bin/sh", "-c", "set -e -x; cp -f /etc/kube-flannel/cni-conf.json /etc/cni/net.d/10-flannel.conf; while true; do sleep 3600; done" ]
volumeMounts:
- name: cni
mountPath: /etc/cni/net.d
- name: flannel-cfg
mountPath: /etc/kube-flannel/
volumes:
- name: run
hostPath:
path: /run
- name: cni
hostPath:
path: /etc/cni/net.d
- name: flannel-cfg
configMap:
name: kube-flannel-cfg
kubectl apply -f kube-flannel.yml
extend kube-discovery replicas to 3
kubectl scale deploy/kube-discovery --replicas=3 -n kube-system
lable master nodes
kubectl label node s7kuberma02.buyabs.corp kubeadm.alpha.kubernetes.io/role=master
kubectl label node s7kuberma03.buyabs.corp kubeadm.alpha.kubernetes.io/role=master
let’s check the kube-system pod to see if all the compoment runs well
[root@s7kuberma01 ~]# kubectl get pods -n kube-system
dummy-2088944543-481qm 1/1 Running 0 27m
kube-apiserver-s7kuberma01.buyabs.corp 1/1 Running 0 28m
kube-apiserver-s7kuberma02.buyabs.corp 1/1 Running 0 16m
kube-apiserver-s7kuberma03.buyabs.corp 1/1 Running 0 17m
kube-controller-manager-s7kuberma01.buyabs.corp 1/1 Running 0 28m
kube-controller-manager-s7kuberma02.buyabs.corp 1/1 Running 0 16m
kube-controller-manager-s7kuberma03.buyabs.corp 1/1 Running 0 17m
kube-discovery-1769846148-48z5n 1/1 Running 0 27m
kube-discovery-1769846148-7ww6t 1/1 Running 0 6m
kube-discovery-1769846148-z9c9w 1/1 Running 0 6m
kube-dns-2924299975-3dlrn 4/4 Running 0 16m
kube-dns-2924299975-5927t 4/4 Running 0 16m
kube-dns-2924299975-cxgqf 4/4 Running 0 27m
kube-flannel-ds-7ms01 2/2 Running 0 12m
kube-flannel-ds-87cf8 2/2 Running 0 12m
kube-flannel-ds-sqs8j 2/2 Running 0 12m
kube-proxy-73c5r 1/1 Running 0 17m
kube-proxy-p52m2 1/1 Running 0 27m
kube-proxy-tfgrc 1/1 Running 0 17m
kube-scheduler-s7kuberma01.buyabs.corp 1/1 Running 0 27m
kube-scheduler-s7kuberma02.buyabs.corp 1/1 Running 0 16m
kube-scheduler-s7kuberma03.buyabs.corp 1/1 Running 0 17m
looks good to me
Keepalived
but now the VIP is only on the s7kuberma01, so we need install keepalived in the 3 master nodes to make sure one master down the others can handle the jobs.
Install Keepalived in all 3 master nodes
vi /etc/keepalived/keepalived.conf
s7kuberma01 keepalived configuration
vrrp_script CheckK8sMaster {
script "curl -k https://10.1.51.31:6443"
interval 3
timeout 9
fall 2
rise 2
}
vrrp_instance VI_1 {
state MASTER
interface ens160
virtual_router_id 61
priority 115
advert_int 1
unicast_src_ip 10.1.51.31
nopreempt
authentication {
auth_type PASS
auth_pass 1234567890
}
unicast_peer {
#10.1.51.31
10.1.51.32
10.1.51.33
}
virtual_ipaddress {
10.1.51.30/25
}
track_script {
CheckK8sMaster
}
}
s7kuberma02 keepalived configuration
vrrp_script CheckK8sMaster {
script "curl -k https://10.1.51.32:6443"
interval 3
timeout 9
fall 2
rise 2
}
vrrp_instance VI_1 {
state BACKUP
interface ens160
virtual_router_id 61
priority 114
advert_int 1
unicast_src_ip 10.1.51.32
nopreempt
authentication {
auth_type PASS
auth_pass 1234567890
}
unicast_peer {
10.1.51.31
#10.1.51.32
10.1.51.33
}
virtual_ipaddress {
10.1.51.30/25
}
track_script {
CheckK8sMaster
}
}
s7kuberma03 keepalived configuration
vrrp_script CheckK8sMaster {
script "curl -k https://10.1.51.33:6443"
interval 3
timeout 9
fall 2
rise 2
}
vrrp_instance VI_1 {
state BACKUP
interface ens160
virtual_router_id 61
priority 113
advert_int 1
unicast_src_ip 10.1.51.33
nopreempt
authentication {
auth_type PASS
auth_pass 1234567890
}
unicast_peer {
10.1.51.31
10.1.51.32
#10.1.51.33
}
virtual_ipaddress {
10.1.51.30/25
}
track_script {
CheckK8sMaster
}
}
- “vrrp_script CheckK8sMaster” “curl -k https://10.1.51.31:6443” to check if the local server kuber-apiserver works
- s7kuberma01 “state MASTER” and the others two “state BACKUP”
- “priority 115” and decrease in 02,03
- change the related ip addresses
start keepalived and check the service status
systemctl enable keepalived;systemctl restart keepalived
check ip address
[root@s7kuberma01 ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens160: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000
link/ether 00:0c:29:4d:0a:87 brd ff:ff:ff:ff:ff:ff
inet 10.1.51.31/25 brd 10.1.51.127 scope global ens160
valid_lft forever preferred_lft forever
inet 10.1.51.30/25 scope global secondary ens160
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe4d:a87/64 scope link
valid_lft forever preferred_lft forever
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN
link/ether 02:42:c3:25:5c:ad brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 scope global docker0
valid_lft forever preferred_lft forever
4: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN
link/ether d6:f2:0f:3c:14:a1 brd ff:ff:ff:ff:ff:ff
inet 10.244.0.0/32 scope global flannel.1
valid_lft forever preferred_lft forever
inet6 fe80::d4f2:fff:fe3c:14a1/64 scope link
valid_lft forever preferred_lft forever
5: cni0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP
link/ether 0a:58:0a:f4:00:01 brd ff:ff:ff:ff:ff:ff
inet 10.244.0.1/24 scope global cni0
valid_lft forever preferred_lft forever
inet6 fe80::e4c5:bdff:fe59:b90d/64 scope link
valid_lft forever preferred_lft forever
6: vethc7ea64c1@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP
link/ether e6:c5:bd:59:b9:0d brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet6 fe80::e4c5:bdff:fe59:b90d/64 scope link
valid_lft forever preferred_lft foreve
check the kubelet status
[root@s7kuberma01 ~]# systemctl status kubelet
● kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/etc/systemd/system/kubelet.service; enabled; vendor preset: disabled)
Drop-In: /etc/systemd/system/kubelet.service.d
└─10-kubeadm.conf
Active: active (running) since Fri 2017-01-13 07:34:03 PST; 2h 0min ago
Docs: http://kubernetes.io/docs/
Main PID: 2333 (kubelet)
CGroup: /system.slice/kubelet.service
├─2333 /usr/bin/kubelet --kubeconfig=/etc/kubernetes/kubelet.conf --require-kubeconfig=true --pod-manifest-path=/etc/kubernetes/manifests --allow-privileged=true --network-plugin=cni --cni-conf-dir=/etc/cni/net.d --cni-bin-dir=/opt/cni/bin --cluster-dns=10...
└─2385 journalctl -k -f
Jan 13 09:33:15 s7kuberma01.buyabs.corp kubelet[2333]: I0113 09:33:15.828445 2333 operation_executor.go:917] MountVolume.SetUp succeeded for volume "kubernetes.io/secret/e7f95c50-d9a5-11e6-80da-000c294d0a87-default-token-x1c6v" (spec.Name: "default-token-x1c6v") p...
Jan 13 09:33:22 s7kuberma01.buyabs.corp kubelet[2333]: I0113 09:33:22.853280 2333 operation_executor.go:917] MountVolume.SetUp succeeded for volume "kubernetes.io/configmap/148c9948-d9a8-11e6-80da-000c294d0a87-flannel-cfg" (spec.Name: "flannel-c...0da-000c294d0a87").
Jan 13 09:33:22 s7kuberma01.buyabs.corp kubelet[2333]: I0113 09:33:22.853334 2333 operation_executor.go:917] MountVolume.SetUp succeeded for volume "kubernetes.io/secret/148c9948-d9a8-11e6-80da-000c294d0a87-default-token-x1c6v" (spec.Name: "default-token-x1c6v") p...
Jan 13 09:33:41 s7kuberma01.buyabs.corp kubelet[2333]: I0113 09:33:41.824006 2333 operation_executor.go:917] MountVolume.SetUp succeeded for volume "kubernetes.io/secret/e80166d2-d9a5-11e6-80da-000c294d0a87-default-token-x1c6v" (spec.Name: "default-token-x1c6v") p...
Jan 13 09:34:27 s7kuberma01.buyabs.corp kubelet[2333]: I0113 09:34:27.892885 2333 operation_executor.go:917] MountVolume.SetUp succeeded for volume "kubernetes.io/secret/d9f40ad4-d9a5-11e6-80da-000c294d0a87-default-token-x1c6v" (spec.Name: "default-token-x1c6v") p...
Jan 13 09:34:34 s7kuberma01.buyabs.corp kubelet[2333]: I0113 09:34:34.818039 2333 operation_executor.go:917] MountVolume.SetUp succeeded for volume "kubernetes.io/secret/db71de39-d9a5-11e6-80da-000c294d0a87-clusterinfo" (spec.Name: "clusterinfo"...0da-000c294d0a87").
Jan 13 09:34:34 s7kuberma01.buyabs.corp kubelet[2333]: I0113 09:34:34.818046 2333 operation_executor.go:917] MountVolume.SetUp succeeded for volume "kubernetes.io/secret/db71de39-d9a5-11e6-80da-000c294d0a87-default-token-x1c6v" (spec.Name: "default-token-x1c6v) p...
Jan 13 09:34:38 s7kuberma01.buyabs.corp kubelet[2333]: I0113 09:34:38.832263 2333 operation_executor.go:917] MountVolume.SetUp succeeded for volume "kubernetes.io/configmap/148c9948-d9a8-11e6-80da-000c294d0a87-flannel-cfg" (spec.Name: "flannel-c...0da-000c294d0a87").
Jan 13 09:34:38 s7kuberma01.buyabs.corp kubelet[2333]: I0113 09:34:38.832812 2333 operation_executor.go:917] MountVolume.SetUp succeeded for volume "kubernetes.io/secret/e7f95c50-d9a5-11e6-80da-000c294d0a87-default-token-x1c6v" (spec.Name: "default-token-x1c6v") p...
Jan 13 09:34:38 s7kuberma01.buyabs.corp kubelet[2333]: I0113 09:34:38.832895 2333 operation_executor.go:917] MountVolume.SetUp succeeded for volume "kubernetes.io/secret/148c9948-d9a8-11e6-80da-000c294d0a87-default-token-x1c6v" (spec.Name: "default-token-x1c6v") p...
Hint: Some lines were ellipsized, use -l to show in full.
Add slave nodes
Run kubeadm join on the s7kubema02 and s7kubema03
[root@s7kubersla01 ~]# kubeadm join --token=2dd145.8c687822f02702f1 10.1.51.30
[kubeadm] WARNING: kubeadm is in alpha, please do not use it for production clusters.
[preflight] Running pre-flight checks
[tokens] Validating provided token
[discovery] Created cluster info discovery client, requesting info from "http://10.1.51.30:9898/cluster-info/v1/?token-id=2dd145"
[discovery] Cluster info object received, verifying signature using given token
[discovery] Cluster info signature and contents are valid, will use API endpoints [https://10.1.51.30:6443]
[bootstrap] Trying to connect to endpoint https://10.1.51.30:6443
[bootstrap] Detected server version: v1.5.2
[bootstrap] Successfully established connection with endpoint "https://10.1.51.30:6443"
[csr] Created API client to obtain unique certificate for this node, generating keys and certificate signing request
[csr] Received signed certificate from the API server:
Issuer: CN=kubernetes | Subject: CN=system:node:s7kubersla01.buyabs.corp | CA: false
Not before: 2017-01-13 17:41:00 +0000 UTC Not After: 2018-01-13 17:41:00 +0000 UTC
[csr] Generating kubelet configuration
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/kubelet.conf"
Node join complete:
* Certificate signing request sent to master and response
received.
* Kubelet informed of new secure connection details.
Run 'kubectl get nodes' on the master to see this machine join.
check the nodes
[root@s7kuberma01 ~]# kubectl get nodes
NAME STATUS AGE
s7kuberma01.buyabs.corp Ready,master 2h
s7kuberma02.buyabs.corp Ready,master 2h
s7kuberma03.buyabs.corp Ready,master 2h
s7kubersla01.buyabs.corp Ready 2m
s7kubersla02.buyabs.corp Ready 5s